摘要
- Uber Hadoop 文件系统最佳实践
- Scaling out using ViewFs
- HDFS upgrades
- NameNode Garbage collection
- Controlling the number of small files
- DFS load management service
- New Feature : Observer NameNode
- Router-based HDFS Federation
- Engineering : 独立的群集(isolated clusters)、分阶段升级过程(a staged upgrade process)和应急回滚计划(contingency rollback plans)
Introduction | Apache Hadoop 简介
Core Concept | Apache Hadoop 核心概念
- MapReduce: Simplified Data Processing on Large Clusters
- The Google File System
Concept A
Concept B
Concept C
Architecture | Apache Hadoop 架构
Best Practice | Apache Hadoop 最佳实践
Uber Hadoop 文件系统最佳实践
- 原文:April 5, 2018 Scaling Uber’s Apache Hadoop Distributed File System for Growth
How Uber implemented these improvements to facilitate the continued growth, stability, and reliability of our storage system.
三年前, Uber 工程团队引入 Hadoop 作为大数据分析的存储 (HDFS) 和计算 (YARN) 基础设施。
Uber 使用 Hadoop 进行批量和流式分析, 广泛应用于包括欺诈检测( fraud detection)、机器学习(machine learning)和 ETA 计算(Estimated Time of Arrival)等领域。在过去的几年里, Uber 的业务发展迅猛,数据量和相关的访问负载呈指数级增长 ; 仅在 2017年, 存储在 HDFS 上的数据量就增长了400% 以上。
在扩展基础设施的同时保持高性能可不是一件轻松的事。为了实现这一目标,Uber 数据架构团队通过实施若干新的调整和功能来扩展 HDFS , 包括可视化文件系统(View File System ,ViewFs)、频繁的 HDFS 版本升级、NameNode 垃圾回收调整, 限制通过系统筛选小文件的数量、HDFS 负载管理服务和只读 NameNode 副本。下面将详细介绍如何执行这些改进以促进存储系统的持续增长、稳定性和可靠性。
Challenges
HDFS 被设计为可伸缩的分布式文件系统, 单个群集支持上千个节点。只要有足够的硬件, 在一个集群中可以轻松、快速地扩展实现超过 100 pb 的原始存储容量。
然而对于 Uber 而言, 业务迅速增长使其难以可靠地进行扩展同时而不减慢数据分析的速度。成千上万的用户每周都要执行数以百万计的查询(通过 Hive 或 Presto )。
目前, HDFS 超过一半以上的访问源于 Presto, 并且 90% 的 Presto 查询需要 100 秒以上的时间来处理。如果我们的 HDFS 基础结构超载, 那么在队列中的查询就会堆积起来, 从而导致查询延迟。更为重要的是,对于每个查询而言,我们需要在 HDFS 上尽快地提供数据。
针对原来的存储基础架构, 我们设计了提取(extract)、转换(transform)和加载 (ETL) 机制以便在用户运行查询时减少同一集群中发生的复制延迟。这些群集由于具有双重职责,因而需要生成小文件以适应频繁的写入和更新, 这反而进一步堵塞了队列。
在我们面临的挑战中,首要任务是多个团队需要大量的存储数据, 这就决定了不能采用按照用例或组织进行集群分割的方案, 那样反过来会降低效率的同时增加成本。
造成减速的根源 — 在不影响用户体验的情况下扩展 HDFS 的主要瓶颈是 NameNode 的性能和吞吐量, 它包括系统中所有文件的目录树, 用于跟踪保存数据文件的位置。由于所有元数据都存储在 NameNode 中, 因此客户端对 HDFS 群集的请求必须首先通过它。更复杂的是, NameNode 命名空间上的ReadWriteLock 限制了 NameNode 可以支持的最大吞吐量, 因为任何写入请求都将被独占写锁定, 并强制任何其他请求都在队列中等待。
2016 年晚些时候, 我们开始发现 NameNode RPC 队列时间高的问题。有时, NameNode 队列时间可能超过每个请求 500毫秒 (最慢的队列时间达到接近一秒), 这意味着每一个 HDFS 请求在队列中至少等待半秒 — 与我们的正常进程时间(10 毫秒以下)相比, 这是明显的减速。
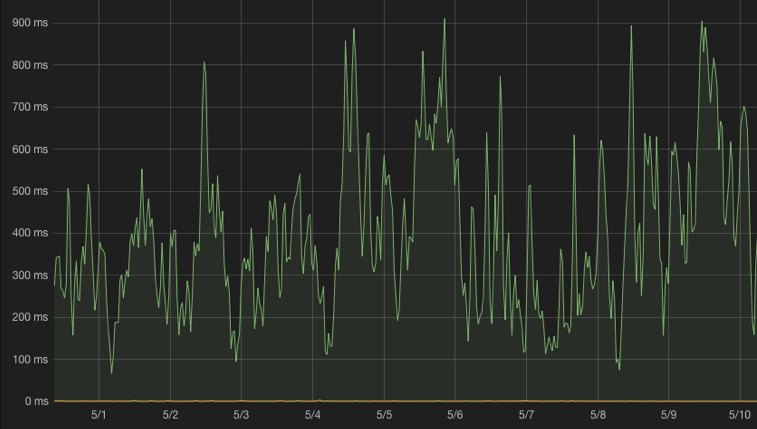
Enabling scaling & improving performance
为了确保 HDFS 高性能运行的同时持续扩展, Uber 并行开发多个解决方案, 以避免在短期内出现停机。这些解决方案使我们建立了一个更可靠和可扩展的系统, 能够支持未来的长期增长。
改进方案概述如下:
Scaling out using ViewFs
Twitter 尝试过类似努力,在他们的启发下, 我们利用可视化文件系统 (ViewFs) 将 HDFS 拆分为多个物理命名空间, 并使用 ViewFs 挂载点向用户呈现一个虚拟命名空间。
为了完成这一目标, 我们将 HBase(YARN 和 Presto 操作)从相同的 HDFS 集群分开。该调整不仅大大减少了主集群上的负载, 而且使我们的 HBase 更加稳定, 将 HBase 集群的重启时间从几小时减少到几分钟。
我们还为聚合 YARN 应用日志创建了一个专用的 HDFS 群集。要使日志聚合支持 ViewFs, 需要 YARN-3269。我们的 Hive 临时目录也被移动到这个群集。增加集群的结果是非常令人满意的 ; 目前, 新群集的服务总写入请求数约占总数的 40%, 而且大多数文件都是小文件, 这也减轻了主群集上的文件计数压力。由于对现有应用程序而言,不需要更改客户端, 因此改转换非常顺利。
最后, 我们在 ViewFs 后端实现了独立的的 HDFS 群集, 而不是基础架构中的 HDFS Federation 。通过这种设置, 可以逐步执行 HDFS 升级, 最大限度地减少大规模停机的风险; 此外, 完全隔离还有助于提高系统的可靠性。然而, 这种修复方案的一个缺点是, 保持单独的 HDFS 群集会导致更高的运营成本。

HDFS upgrades
第二个解决方案是升级 HDFS 以跟上最新版本。我们一年执行了两次主要升级, 首先从 CDH 5.7.2 ( 包含大量 HDFS 2.6.0 补丁) 升级到 Apache 2.7.3, 然后升级到 Apache 2.8.2。为此, 我们还必须重构基于 Puppet 和 Jenkins 之上的部署框架, 以更换第三方群集管理工具。
版本升级带来了关键的可伸缩性改进, 包括 HDFS-9710、HDFS-9198 和 HDFS-9412。例如, 升级到 Apache 2.7.3 后, 增量块报告(incremental block report)的数量明显减少, 从而减轻了 NameNode 的负载。
升级 HDFS 可能会有风险, 因为它可能会导致停机、性能下降或数据丢失。为了解决这些可能的问题, 我们花了几个月的时间来验证 Apache 2.8.2 之后才将其部署到生产环境中。但是, 在升级最大的生产集群时, 仍然有一个 Bug (HDFS-12800) 让我们措手不及。尽管 Bug 引起的问题很晚才发现, 但是凭借独立群集、分阶段升级过程(a staged upgrade process)和应急回滚计划(contingency rollback plans),最后给我们的影响非常有限。
事实证明,在同一台服务器上运行不同版本的 YARN 和 HDFS 的能力对于我们实现扩展至关重要。由于 YARN 和 HDFS 都是 Hadoop 的一部分, 它们通常一起升级。然而, YARN 主线版本的升级需要更长时间的充分验证之后才会推出, 一些生产应用的 YARN 可能需要更新,由于 YARN API 的变化或 YARN 和这些应用的 JAR 依赖冲突。虽然 YARN 的可伸缩性在我们的环境中不是一个问题, 但我们不希望关键的 HDFS 升级被 YARN 升级阻塞。为了防止可能的堵塞, 我们目前运行的 YARN 比 HDFS 的版本更早, 在我们的场景很有效。(但是, 当采用诸如 Erasure Coding 之类的功能时, 由于需要更改客户端, 此策略可能不起作用。)
NameNode Garbage collection
垃圾回收 (Garbage collection , GC) 调优在整个优化方案中也发挥了重要作用。它在扩展存储基础架构的同时,给我们创造了必要的喘息空间。
通过强制使用并发标记扫描收集器 (Concurrent Mark Sweep collectors ,CMS) 防止长时间 GC 暂停, 通过调整 CMS 参数 (如 CMSInitiatingOccupancyFraction、UseCMSInitiatingOccupancyOnly 和 CMSParallelRemarkEnabled ) 来执行更具侵略性的老年代集合(注:CMS 是分代的,新生代和老年代都会发生回收。CMS 尝试通过多线程并发的方式来跟踪对象的可达性,以便减少老生代的收集时间)。虽然会增加 CPU 利用率, 但幸运的是我们有足够的空闲 CPU 来支持此功能。
由于繁重的 RPC 负载, 在新生代中创建了大量短期的对象, 迫使新生代收集器频繁地执行垃圾回收暂停(stop-the-world)。通过将新生代的规模从 1.5GB 增加到 16GB , 并调整 ParGCCardsPerStrideChunk 值 (设置为 32768), 生产环境中 NameNode 在 GC 暂停时所花费的总时间从 13% 减少到 1.7% , 吞吐量增加了 10% 以上。
与 GC 相关的 JVM 参数( NameNode 堆大小 160GB ), 供参考:
1 | XX:+UnlockDiagnosticVMOptions |
Uber 还在评估是否将第一垃圾回收器 (Garbage-First Garbage Collector , G1GC) 集成在系统中。虽然在过去使用 G1GC 时没有看到优势, 但 JVM 的新版本带来了额外的垃圾回收器性能改进, 因此重新审视收集器和配置的选择有时是必要的。
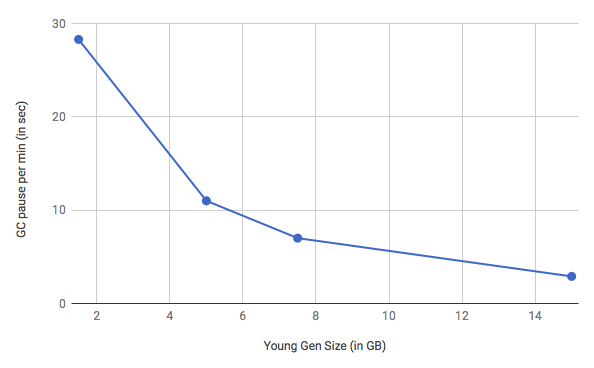
Controlling the number of small files
由于 NameNode 将所有文件元数据加载到内存中, 小文件增长会增加 NameNode 的内存压力。此外, 小文件会导致读取 RPC 调用增加, 以便在客户端读取文件时访问相同数量的数据, 以及在生成文件时增加 RPC 调用。为了减少存储中小文件的数量, Uber 主要采取了两种方法:
首先,Uber Hadoop 数据平台团队基于 Hoodie 库建立了新的摄取管道, 生成比原始数据管道创建的更大的文件。不过, 作为一个临时解决方案, 在这些可用之前, 我们还建立了一个工具 (称为 stitcher “订书机”), 将小文件合并成较大的文件(通常大于 1GB )。
其次, 在 Hive 数据库和应用程序目录上设置了严格的命名空间配额。为了贯彻这一目标, 我们为用户创建了一个自助服务工具, 用于管理其组织内的配额。配额的分配比例为每文件 256MB, 以鼓励用户优化其输出文件大小。Hadoop 团队还提供优化指南和文件合并工具以帮助用户采用最佳实践。例如, 在 Hive 上启用自动合并(auto-merge)和调整减速器数量(the number of reducers )可以大大减少由 Hive insert-overwrite 查询生成的文件数。
HDFS load management service
运行大型多租户基础架构 (如 HDFS ) 的最大挑战之一是检测哪些应用程序导致异常大的负载、如何快速采取措施来修复它们。为了实现这一目的,Uber 构建了内置 HDFS 的负载管理服务, 称为 Spotlight 。
在目前的 Spotlight 实现中, 审计日志从活跃的 NameNode 以流的形式送到一个基于 Flink 和 Kafka 的后端实时处理。最后,日志分析结果通过仪表板输出, 并用于自动化处理(例如自动禁用帐户或杀死导致 HDFS 减速的工作流)。
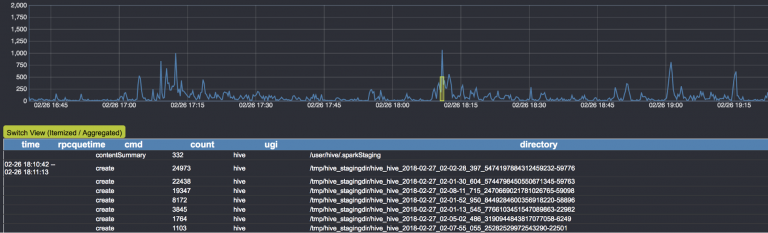
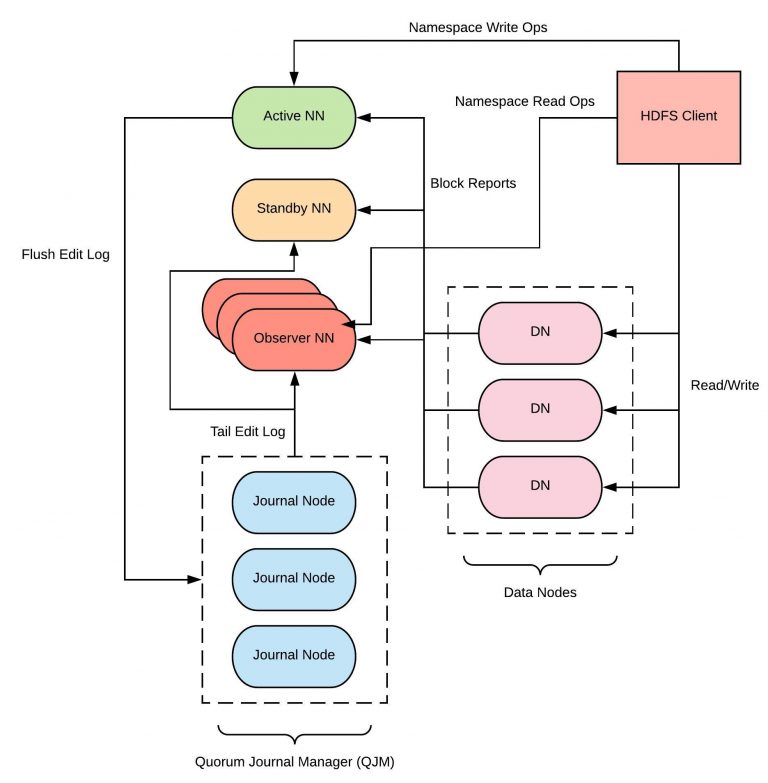
New Feature : Observer NameNode
Uber 正在开发一个新的 HDFS 功能 Observer NameNode (HDFS-12975) 。 Observer NameNode 设计为一个 NameNode 只读副本, 目的是减少在活跃的 NameNode 群集上加载。由于 HDFS RPC 容量和增长的一半以上来自只读的 Presto 查询, Uber 希望借助 Observer NameNodes 的帮助将总体 NameNode 吞吐量扩展到 100% 。Uber 已经完成了这个工具的验证, 并正在将其投入生产环境中。
最佳实践
- Layer your solutions: 考虑不同层次的解决方案。实现像 Observer NameNode 那样的工具或将 HDFS 切分到多集群需要付出巨大的努力。短期措施, 如 GC 调整和通过 stitcher 合并较小的文件, 给了我们很多喘息的空间以开发完善长期的解决方案。
- Bigger is better: 因为小文件对 HDFS 的威胁, 所以最好及早解决它们, 而不是延后。主动向用户提供工具、文档和培训是帮助实施最佳实践非常有效的方法。
- Participate in the community: Hadoop 已经存在超过 10 年了, 其社区比以往任何时候都更加活跃, 几乎每个版本中都引入了可伸缩性和功能改进。通过贡献您自己的发现和工具来参与 Hadoop 社区对于你持续扩展基础架构非常重要。
未来
在不久的将来, Uber 计划将各种新服务集成到存储系统(如 图6 所示)。
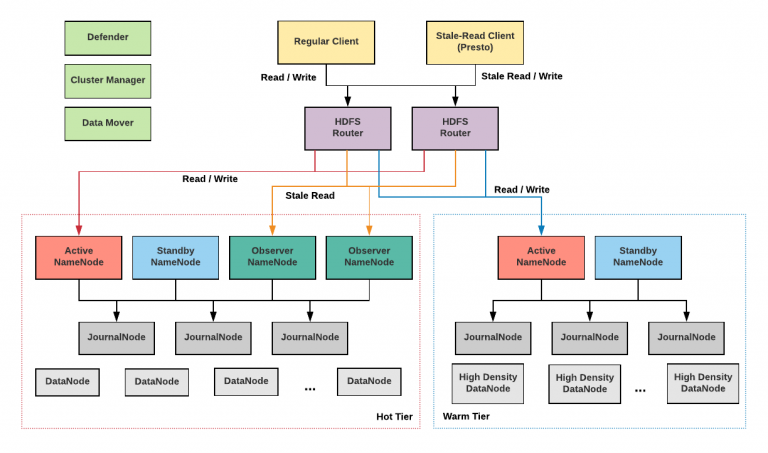
接下来重点介绍两个主要项目, 基于路由的 HFDS Federation 和 tiered storage :
Router-based HDFS Federation
Uber 目前使用 ViewFs 扩展 HDFS (当 subclusters 超载时)。此方法的主要问题是, 每次在 ViewFs 上添加或替换新的挂载点时, 都需要更改客户端配置, 而且很难在不影响生产工作流的情况下进行。这种困境是我们目前只拆分不需要大规模更改客户端数据的主要原因之一, 例如 YARN 日志聚合。
Microsoft 的新倡议—基于路由的 HFDS Federation (HDFS-10467, HDFS-12615),目前包含在 HDFS 2.9 版本中, 是一个基于 ViewFs 的分区联盟的扩展。该联盟添加了一层软件集中管理 HDFS 命名空间。通过提供相同的接口 (RPC 和 WebHDFS 的组合), 它的外层为用户提供了对任何 subclusters 的透明访问, 并让 subclusters 独立地管理其数据。
通过提供再平衡工具( a rebalancing tool ), 联盟层( the federation layer )还将支持跨 subclusters 的透明数据移动, 用于平衡工作负载和实现分层存储。联盟层集中式维护状态存储区中全局命名空间的状态, 并允许多个活跃的路由器将用户请求定向到正确的 subclusters 时启动和运行。
Uber 正在积极地与 Hadoop 社区密切协作,致力于将基于路由的 HDFS Federation 引入到生产环境, 并进一步开源改进, 包括支持 WebHDFS 。
Tiered Storage
随着基础架构的规模增长, 降低存储成本的重要性也同样重要。Uber 技术团队中进行的研究表明, 相较旧数据 (warm data) 用户会更频繁地访问最近的数据 (hot data)。将旧数据移动到一个单独的、占用较少资源的层将大大降低我们的存储成本。HDFS Erasure Coding 、Router-based Federation、高密度 (250TB 以上) 硬件和数据移动服务 (在 “热” 层群集和 “暖” 层群集之间处理移动数据) 是即将进行的分层存储设计的关键组件。Uber 计划在以后的文章中分享在分层存储实现方面的经验。
Apache Hadoop ABC
1 | $ hadoop version |
Java Garbage Collection Types
Serial GC (-XX:+UseSerialGC): Serial GC uses the simple mark-sweep-compact approach for young and old generations garbage collection i.e Minor and Major GC.
Serial GC is useful in client-machines such as our simple stand alone applications and machines with smaller CPU. It is good for small applications with low memory footprint.Parallel GC (-XX:+UseParallelGC): Parallel GC is same as Serial GC except that is spawns N threads for young generation garbage collection where N is the number of CPU cores in the system. We can control the number of threads using -XX:ParallelGCThreads=n JVM option.
Parallel Garbage Collector is also called throughput collector because it uses multiple CPUs to speed up the GC performance. Parallel GC uses single thread for Old Generation garbage collection.Parallel Old GC (-XX:+UseParallelOldGC): This is same as Parallel GC except that it uses multiple threads for both Young Generation and Old Generation garbage collection.
Concurrent Mark Sweep (CMS) Collector (-XX:+UseConcMarkSweepGC): CMS Collector is also referred as concurrent low pause collector. It does the garbage collection for Old generation. CMS collector tries to minimize the pauses due to garbage collection by doing most of the garbage collection work concurrently with the application threads.
CMS collector on young generation uses the same algorithm as that of the parallel collector. This garbage collector is suitable for responsive applications where we can’t afford longer pause times. We can limit the number of threads in CMS collector using -XX:ParallelCMSThreads=n JVM option.G1 Garbage Collector (-XX:+UseG1GC): The Garbage First or G1 garbage collector is available from Java 7 and it’s long term goal is to replace the CMS collector. The G1 collector is a parallel, concurrent, and incrementally compacting low-pause garbage collector.
Garbage First Collector doesn’t work like other collectors and there is no concept of Young and Old generation space. It divides the heap space into multiple equal-sized heap regions. When a garbage collection is invoked, it first collects the region with lesser live data, hence “Garbage First”. You can find more details about it at Garbage-First Collector Oracle Documentation.
扩展阅读:电子书《Linux Perf Master》

扩展阅读:开源架构技术漫谈
- 开源架构技术漫谈:Hadoop
- 基于Kafka构建事件溯源型微服务
- 基于Go语言快速构建一个RESTful API服务
- 数据可视化(三)基于 Graphviz 实现程序化绘图
- SDN 技术指南(一): 架构概览
- SDN 技术指南(二): OpenFlow
- 浅谈基于数据分析的网络态势感知
- 网络数据包的捕获与分析(libpcap、BPF及gopacket)
- 计算机远程通信协议:从 CORBA 到 gRPC
- 基于LVS的AAA负载均衡架构实践
- 基于Ganglia实现服务集群性能态势感知
- Stack Overflow:云计算平台的趋势分析
- Stack Overflow:2017年最赚钱的编程语言
- Stack Overflow: The Architecture & Hardware - 2016 Edition

