摘要
- 基于 Go + R 可视化古典音乐作曲家社交网络
- Coperformance 是一个业余项目,融合了作者对编程,数据和古典音乐的兴趣爱好。
- Key Words: Go , R , Composer , Visualization

- 原标题:Using Data to Visualize Connections Between Composers
- 链接:https://overthinkdciscores.com/2018/12/03/using-data-to-visualize-connections-between-composers
- 作者:Evan Murray
- 发表时间:12/03/2018
编程很有趣。我们能够制作很酷的东西,甚至无需考虑它对现实世界是否有实际用途。Coperformance 是一个业余项目,融合了作者对编程,数据和古典音乐的兴趣爱好。通过可视化应用 —— 我们可以从一个新的角度理解古典音乐作曲家以及他们之间的微妙联系。
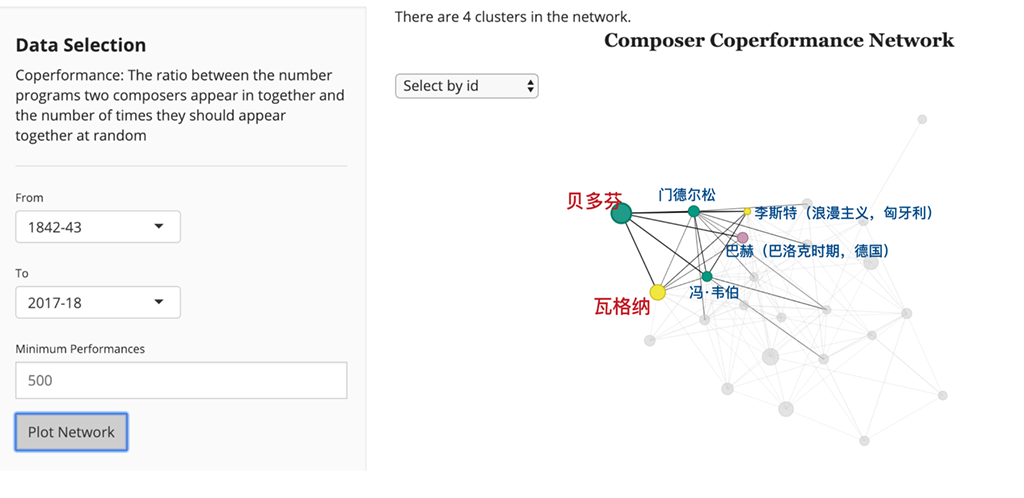
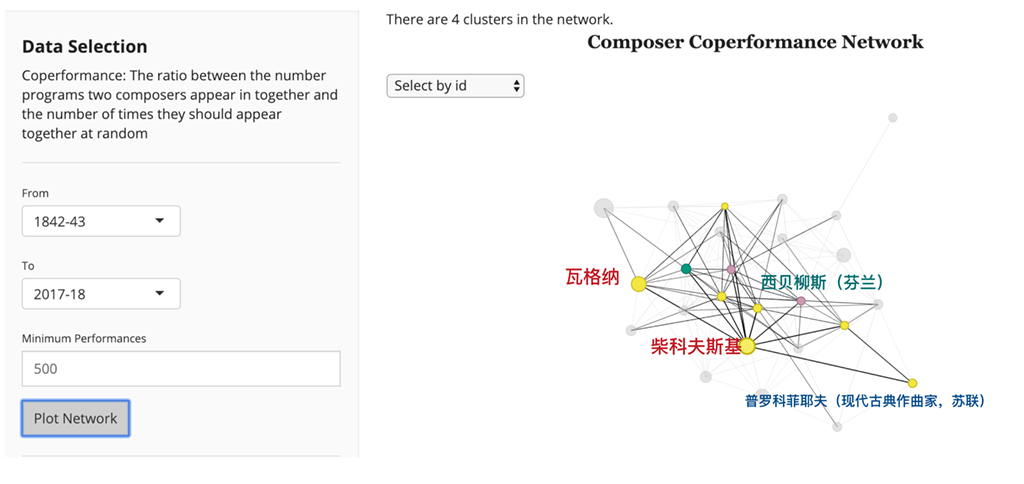
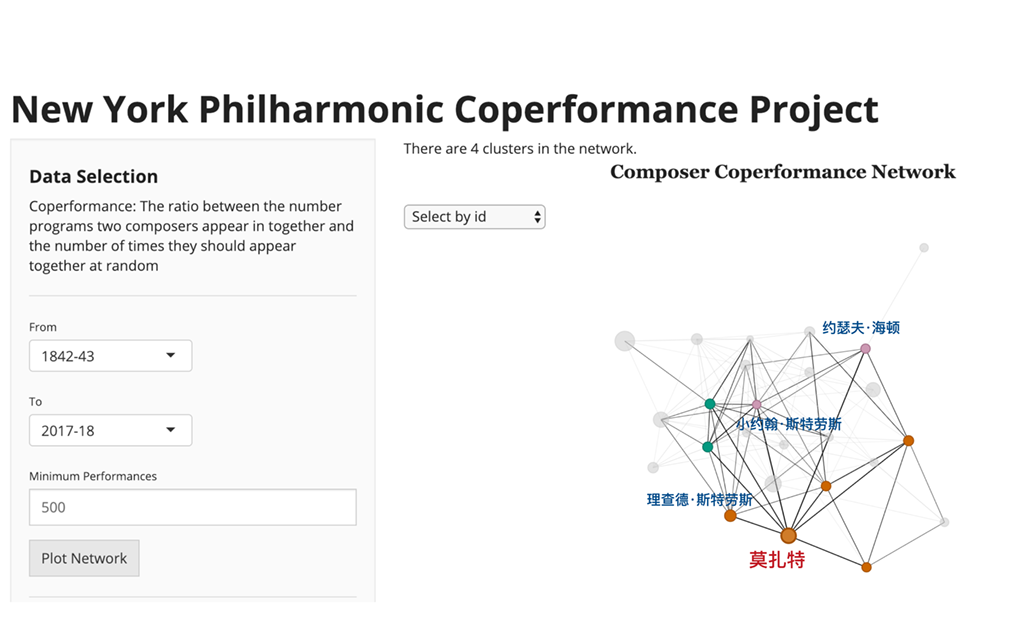
该项目得以实现归功于纽约爱乐乐团这座艺术宝库 —— 它们建立了一个 Github 库以保存该团历史上所有的演出曲目。库中包含了大量信息,包括演出时间、地点,作曲家信息,独奏者信息,甚至是幕间休息的数据。这些数据都以 XML 或 JSON 格式编码,任何编程语言都可以解析和分析。
1 | { |
定义指标
- 定义新指标:Coperformance
鉴于演出历史库包含丰富的数据,我们最直接简单的想法是探索作曲家之间的联系 —— 作曲家在同一个演出中出现的频率是多少?我们使用这个指标是因为音乐总监经常根据主题将不同曲目放在一起,比如浪漫英雄主义(Romantic heroism),例如芝加哥交响乐团在安娜堡(Ann Arbor,密歇根州)演出曲目,包括贝多芬第五交响曲和马勒第一交响曲。
连接两个作曲家的原因多种多样。可能是缘于他们都创作类似的音乐——使用相同的形式和技巧、以不同的方式,或者由一个有趣的传记联系在一起。无论是什么,我们都期望它会导致两个作曲家比其他人更频繁地编排在一起。我们可以基于纽约爱乐乐团的数据库探索这些联系,因为数据的特殊性和令人难以置信的时间跨度,甚至可以追溯到爱乐乐团历史上的第一季。
为此,首先定义一个名为“Coperformance”指标。 Coperformance 值为:两位作曲家在同一节目中出现的次数和随机出现次数的比率。如果它的值大于 1,可以说两位作曲家以某种非常规的方式联系在一起。如果它的值小于或等于1,那么可以说这两位作曲家直接没有联系。
例子。假设每 100 场节目中就有 1 场同时出现两位作曲家。为了简化数学运算,数据库中有一百万场演出。如果作曲家只是随机出现,我们假设所有节目中有第一位作曲家出现的概率为 1% ,第二位作曲家出现的概率也为 1%,即所有节目中两位作曲家同时出现的概率为 0.01%(本例中为100场)。事实上,如果两位作曲家一起出现在 200 个程序中,那么 Coperformance 值就是2,数据显示他们之间的联系非常紧密。如果他们只出现在 90 个节目中,那么从数据上看,没有证据表明两位作曲家之间有任何联系,除了他们都是古典音乐作曲家而已。
需要说明的是,Coperformance 指标只能衡量作曲家之间的链接数量,并不知道驱动链接的原因。如前所述,可能有各种各样的事物将作曲家联系起来并提高 Coperformance 值,从音乐风格到传记信息,“也许音乐总监喜欢两位作曲家的美学”。要弄清楚具体是什么驱动链接,需要另外检查它们出现在相同演出的原因,看看是否存在共同主题。
指标可视化
Coperformance 指标可视化可以基于社交网络(Social networks)实现。
交友软件一般都是典型的社交网络,例如 Facebook/QQ/微信。社交网络主要由两部分组成:节点(nodes)和边(edges)。节点是网络中的个人,边是连接两个节点的线,就像两个 Facebook 好友一样。在我们的例子中,边是二元的和非定向的(两个人要么是、要么不是朋友;如果你不是我的朋友,我不能成为你的朋友)。实际上,边可以有不同的权重,也可以是定向的。
在作曲家网络中,每个节点都是一个单独的作曲家,边是加权的,并通过 Coperformance 值表示具有相同链接的作曲家。如果一对作曲家的 Coperformance 值大于 1,他们之间就具有强化联系,如果 Coperformance 值小于或等于 1 就不会。我们可以通过调整边的权重,使得变的线条更大、颜色更深(通过Coperformance 表现强化链接)进一步可视化网络。也可以对节点做类似的事情,使作曲家的节点根据他们在演出历史中出现的次数而变得越来越大或越来越小。
最后,可视化工具为了使网络更加漂亮,可以将作曲家分组为集群(clusters)或社区(communities)。如果几个作曲家交织在一起,那么他们彼此都会有很高的 Coperformance 值。这有点类似于 Facebook 上的社交圈(social clique)。集群可视化的实现方式简单说就是根据它们所属的社区对节点进行着色。对此,有两点需要特别说明:
首先,关于聚类算法的工作原理超出了本文的范围,可以参考 Wikipedia page on social network analysis 。
其次,就像 Coperformance 值无法解释将作曲家链接在一起的原因一样,聚类算法也无法解释到底是什么原因导致聚集发生。这是属于音乐导演和音乐学家需要回答的问题,而不属于数学领域。
总而言之,作曲家网络的节点代表单个作曲家,并且具有两个属性:大小表示他们上演的频率和颜色表示他们在网络中所属的集群。网络中的边表示作曲家之间的链接情况,随着连接变得越来越强边也就变得越来越大、颜色越来越深。
可视化编程
构建作曲家网络的过程可以分为三个主要步骤:从格式化文件中读取数据,迭代数据中的所有成对出现的作曲家以计算其 Coperformance 值,网络可视化。
Go 语言在前两个步骤中表现非常棒,但它没有任何网络可视化软件包可以在易用性和功能性方面媲美 R igraph 和 R visNetwork 。此外,相比于类似的 Go 软件包,Rstudio shiny 在构建用户界面和下载数据方面更具优势。自然地,该项目使用 sexp 包(注:原作者编写的开源代码库)。上述所有元素组合在一起部署在服务器上,就可以实现作曲家网络及可视化应用。
使用说明。用户指定数据范围(开始和结束时间)以及网络中需要包含的作曲家的Coperformance 指标最小值。
首先,程序将这些数据文件的名称从 R(和 shiny 包)传递给 Go (使用 sexp 包)。然后,Go 读取文件,根据用户的规范解析数据,计算网络中所有作曲家成对出现的 Coperformance 值,并将结果写入用户可以下载的 JSON 和 csv 数据文件。接下来从 Go 获取数据文件名(通过 sexp 传递),计算网络中的集群,并将其可视化。
在这个项目中,虽然在没有 sexp 软件包的情况下几乎不会像现在这样干净,但它确实暴露了 sexp 软件包的弱点。通过文件连接 R 语言和 Go 语言太麻烦了,因为 sexp 不支持在 R 语言和 Go 语言之间传递矩阵(matrix)或字符串向量 (vector)。使 sexp 软件包更加灵活、缩小这一差距,将是我接下来的首要工作。
如果利用统计数据还可以改进作曲家网络。从统计学上讲,两位作曲家随机出现的出场次数不是一个特定的数字(如上例中的 100),而是基于概率的一系列数字。
如果将实际观测到的次数与我们认为合适的显着性水平(可能为95%)的上限进行比较,则可能更准确。例如,在上面的案例中将是 101 而不是 100 。(编者注:由于假设检验是根据样本提供的信息进行推断的,也就有犯错误的可能。例如,原假设正确,而我们却把它当成错误的加以拒绝。犯这种错误的概率用 α 表示,统计上把 α 称为假设检验中的显著性水平,也就是决策中所面临的风险。它是公认的小概率事件的概率值,必须在每一次统计检验之前确定,通常取α=0.05 或 α=0.01 。这表明,当作出接受原假设的决定时,其正确的可能性/概率为 95% 或 99%)
Tips
New York Philharmonic
纽约爱乐(New York Philharmonic),正式全名为纽约爱乐交响乐协会(Philharmonic-Symphony Society of New York, Inc.),世界上历史最悠久的乐队之一, 1842 年在美国纽约市成立。纽约爱乐是美国成立时间最长的乐团,属于美国五大管弦乐团之一。纽约爱乐完成过多个音乐作品的美国首演,例如贝多芬的《第九交响曲》。纽约爱乐目前一年大约演出 180 场音乐会。
芝加哥交响乐团(穆蒂的新东家)的特点是有力量,以机床般强劲的铜管乐器为核心,这主要是由指挥弗里茨·莱纳(Fritz Reiner)带动起来的,后被格奥尔格·佐尔蒂(Georg Solti)进行了略带夸张的演绎;波士顿交响乐团的特点是稍微有点狂热,具有穿透力,很适合它演奏的法国音乐,指挥是查尔斯·明希(Charles Munch)和皮埃尔·蒙度(Pierre Monteux);伦纳德·伯恩斯坦(Leonard Bernstein)领导下的纽约爱乐乐团的特点是态度轻松、随意。—— 《纽约时报》
Chicago Youth Symphony Orchestra
These statistics are of great concern to those within the classical music world, and especially amongst orchestras in Chicago, which is one of America’s most diverse cities. To this end, several of the city’s leading classical music teaching institutions have formed a partnership to understand and enhance their roles in cultivating diverse professional musicians of tomorrow. This group, the Chicago Musical Pathways Initiative, was built to identify talented, motivated students early in their training, provide them with the resources they need to help them achieve their full musical potential, and ultimately to increase diversity in America’s professional, musical landscape.
资源链接
- Project Coperformance Site
- Project Code:New York Philharmonic and Social Network Analysis
- New York Philharmonic Performance History repository
- Wikipedia page on social network analysis
- R Shiny
Shiny is an R package that makes it easy to build interactive web apps straight from R. You can host standalone apps on a webpage or embed them in R Markdown documents or build dashboards. You can also extend your Shiny apps with CSS themes, htmlwidgets, and JavaScript actions. - R visNetwork
visNetwork is an R package for network visualization, using vis.js javascript library (http://visjs.org/) - Project igraph
igraph is a collection of network analysis tools with the emphasis on efficiency, portability and ease of use. igraph is open source and free. igraph can be programmed in R, Python, Mathematica and C/C++. - Project sexp (Rgo)
扩展阅读
音乐史
数据可视化
- 数据可视化(一)思维利器 OmniGraffle 绘图指南
- 数据可视化(二)跑步应用Nike+ Running 和 Garmin Mobile 评测
- 数据可视化(三)基于 Graphviz 实现程序化绘图
- 数据可视化(四)开源地理信息技术简史(Geographic Information System
- 数据可视化(五)基于网络爬虫制作可视化图表
- 数据可视化(六)常见的数据可视化仪表盘(DashBoard)
- 数据可视化(七)Graphite 体系结构详解
- 数据可视化(八)Program,Data and Classical Music
- 数据可视化(十)公共数据源列表

