摘要
- 性能分析的基础:吞吐和响应的区别
- 实际系统中的性能分析
- 性能调优
- 性能测试
- 虚拟化环境下的性能
- 云环境下的性能
一、性能分析的基础
响应和吞吐的区别(初学者可能经常会混淆的概念)
响应:表示应答的快慢
吞吐:表示处理数量的多少
案例:“明明优化了机器的配置,但性能并没有提高”。响应有问题,却增加了CPU核心数,只是增加了空转的CPU核心而已。所以要养成习惯,先确认问题是出在响应还是吞吐上。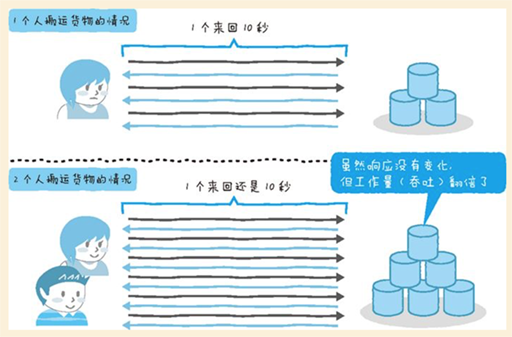
性能分析从测量开始,性能必须是能够测量的
性能信息的3种类型:
1、概要形式:例如sar、vmstat,作为入手点调查过去发生了什么,“现象”
2、事件记录形式:例如网络抓包(Packet Capture)
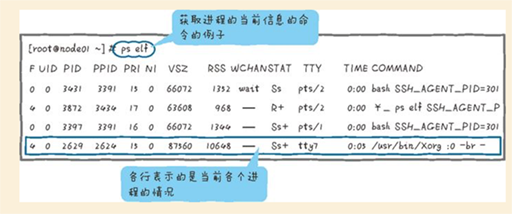
3、快照(Snapshot):例如ps和top
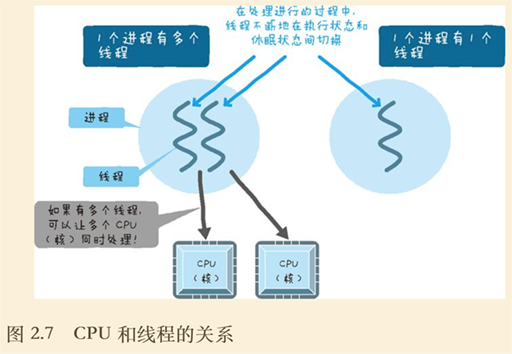
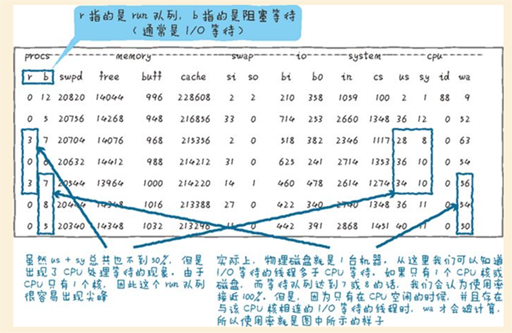
性能分析中的重要理论:等待队列理论
从性能的稳定性方面来考虑,带宽控制思维方式。
二、实际系统中的性能分析
AP服务器的性能测量
不同语言的性能信息获取: Java:GC(垃圾回收)日志 ,全GC(Stop the world)
DB服务器的性能测量
DB服务器本身的特点就是集中管理数据,需要频繁地查看线程(会话)之间的交互,因此很容易出现资源竞争的情况,因此在进行DBMS性能分析的时候,一定要考虑多个线程的存在。
存储性能分析的思路
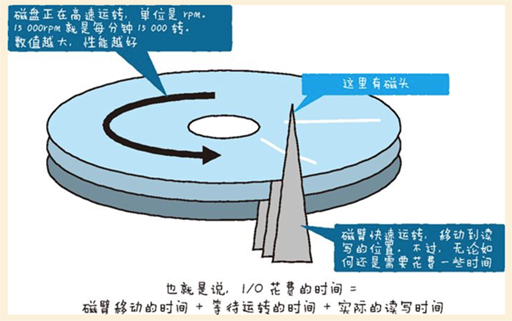
思路:重视IOPS
术语:响应时间、IOPS(Input Output Per Second)
类型:物理磁盘、SSD
缓存命中率:在存储的世界里,磁盘、存储、OS等各处都存在着缓存,使用缓存命中率作为表示缓存工作效率的指标。
脏数据(或者脏数据块):已经更新但没有写入的数据。脏数据不可以丢弃,如果在缓存上堆积了大量的脏数据,I/O就无法有效运作,进而就会导致问题的发生。


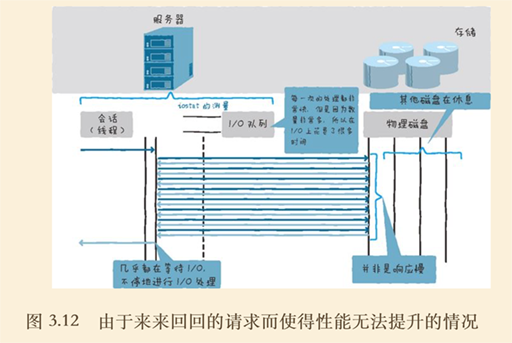
网络性能分析的思路
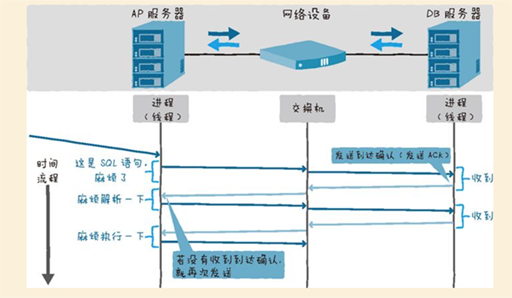
调查原因
- 陷阱1:关注受害者,“疑犯”与“真凶”
- 陷阱2:没有意识到基础不稳 (自下而上)
- 陷阱3:没有注意到负载的变化
- 陷阱4:不能确定谁拿着球
- 陷阱5:不能确定因果关系
很多人不能把握原因,而只是随便瞎猜一下就进行调优。
掌握因果关系的一个窍门是学习架构知识。知道了机制后就能减少错误分析的情况。另外,从逻辑上来考虑因果关系是很重要的。要试着思考一下“这个现象能否解释另一个现象”。
三、性能调优
- 调优要循序渐进:先把大石头移开。
具体思路:
1、重复使用:连接池、PreparedStatement、线程池
2、汇总处理:集中、Piggyback
3、提高速度和实现并行
4、纵向扩展(Scale Up)与横向扩展(Scale Out):应用技巧:
1、省略循环
2、访问频率高的数据存放入键值存储
3、访问频率高的数据存放在使用位置附近
4、把同步变成异步
5、带宽控制
6、LRU算法
7、分割处理或者细化锁的力度
8、回写缓存、多层缓存
9、巨帧和高速网络
10、负载均衡 基于LVS的AAA负载均衡架构实践
11、写时复制

四、性能测试
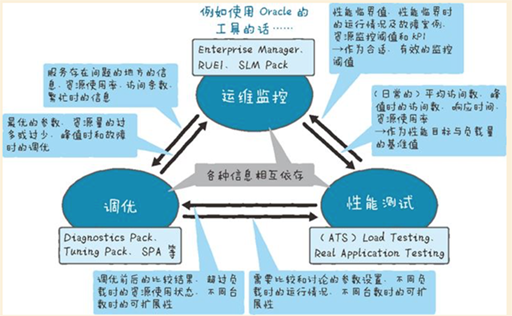
项目工程环境
基于项目整理来确保应用程序的性能。
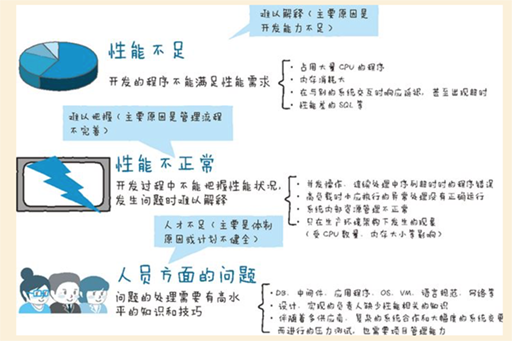
应用程序设计负责人一般不会考虑系统整体的性能,而是满脑子考虑如何使用新的框架和中间件来实现需要的业务和功能。
常见的失败情况:9种反面模式
- 不能在期限内完成
- 性能很差!解决不了性能问题
- 由于没有考虑到环境差异而导致发生问题
- 压力场景设计不完备导致发生问题
- 没有考虑到缓冲、缓存的时候而导致发生问题
- 没有考虑到思考时间而导致发生问题
- 报告内容难以理解导致客户不能认同
- 客户因为存在不信任感而不能认同
- 测试很花时间
后期工程中隐藏着性能问题,原因如下:
- 只有在生产环境中才会出现
- 问题的显现需要很多条件(环境、数据、负载生成)
- 因为特定的操作才导致发生性能问题
==>>为系统中的性能测试流出一个月的时间。
对横跨多个领域的性能问题进行排查的时候,如果不能综合多个领域来考虑,负责人就会一直说“我负责的那部分没有问题”,导致问题无法解决。
客户关心的焦点集中在“在实际生产环境中运行时是否会出现性能方面的问题”。
由于不能很好地共享性能测试地整体过程,或者本来关于性能需求或性能测试设计地需求等地约定就很模糊,导致结论与评价基准等也变得很模糊,引起沟通不畅。
需求定义
三要素:吞吐(T)、响应时间(R)、用户并发度(U)
1 | U x R = T |
并发并不是作为性能目标通过听取客户意见来推导出来的,而是通常根据吞吐和响应时间计算出一个合适的值(客户即使了解业务中同时使用的人数,但是对于系统瞬间运行的并发处理的情况,他们并不清楚)。
集成测试:多并发运行测试
系统测试:压力测试、临界测试、耐久测试
运维测试:性能监控测试、故障测试
五、虚拟化环境下的性能
在虚拟化环境中,多个VM(虚拟机)运行在一台服务器上,因此可以更加有效地共享资源,有利于削减成本。而反过来,若资源被共享过度,则会发生竞争,可能导致性能的下降。因此,在资源效率和性能之间取得平衡就变得尤为重要。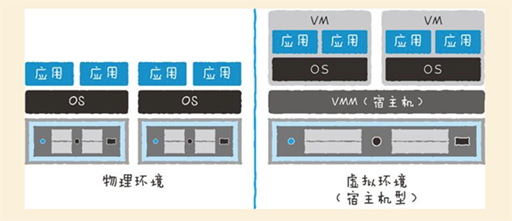

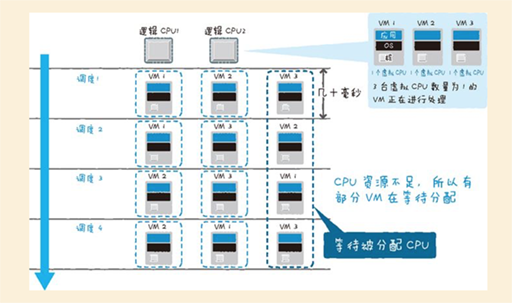
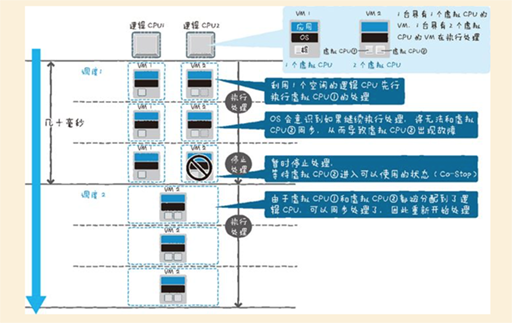
虚拟化的性能管理(CPU)
虚拟环境下Guest OS发出的特权命令会被更改,因此和物理环境相比需要更多的处理时间。另外,物理环境下也不需要将逻辑CPU分配个VM的调度处理,如果CPU的分配发生了竞争,这个等待时间就会影响性能。

六、云计算环境下的性能
- 构成计算资源的技术元素并没有大的变化
- 网络访问和资源的使用及提供形态发生了变化
- LAN网络的变化
- WAN网络的变化
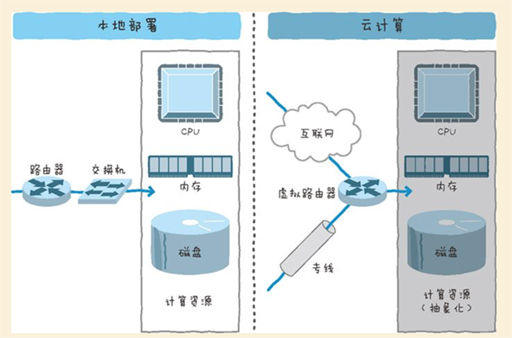
云计算的一个大的变化就是LAN网络。具体来说,本地部署环境下物理路由器和交换机实现的部分被隐藏起来,通过虚拟的网络来组成。
WAN连接方法:
1、专线连接:主要依赖于所选择的通信运营商的服务特性,带宽保证和性能的成本与之前相比并没有太大变化。
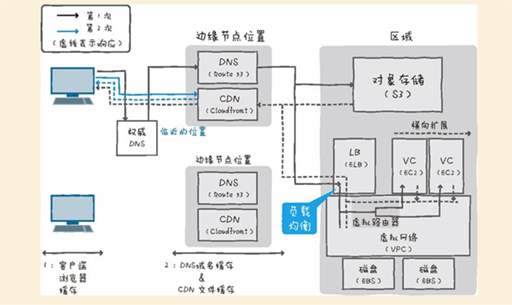
2、互联网连接:云计算服务可以非常优惠的加个来利用共享的互联网带宽,可以减轻高峰时带宽限制的顾虑。云计算服务中提供的CDN(Contents Delivery Network)或Global DNS等功能,能够很方便地提高互联网服务的速度。
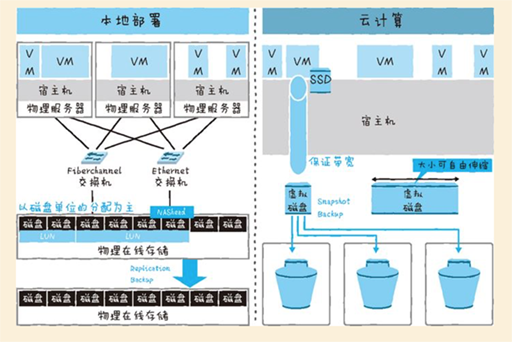
随着存储的网络化,直接连接到普通的LAN的情况也越来越多,磁盘I/O变为网络I/O的情况也越来越多。在NAS(Network Attached Storage)以及云环境下,磁盘I/O在普通的TCP/IP网络中完成的情况也很多。(具体第7章)
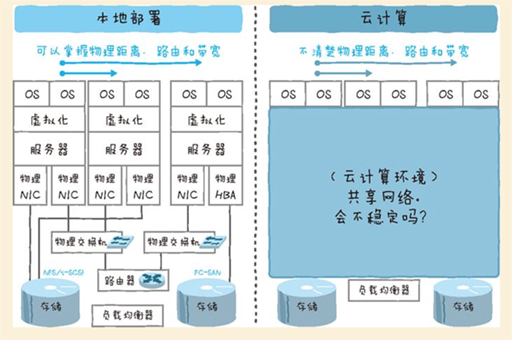
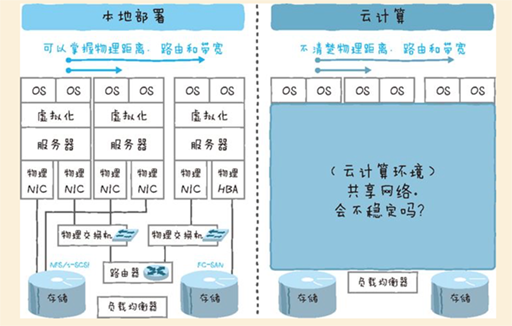
云计算环境中开发阶段的思维方式
在云计算环境下,比起技术方面的差异,思维方式上的差异更为明显。在实际业务层面最大的变化就是对以往的以硬件配置为前提的开发运维流程的影响。
1、基本设计:估算(Sizing)
2、系统测试:性能测试
3、项目管理
云计算环境中不需要准备硬件,但是并不代表不需要进行估算。
观点一:成本估算。成本会根据选定的资源大小而有所变化。
观点二:临界估算。在本地部署环境下,企业级系统很多都是集中式的处理方式,如果按照这种方式原封不懂地迁移到云计算环境,可能就会碰到瓶颈,为了消除这种风险,就需要进行估算,考虑临界容量的可实现性。
POC:Proof of Concept (概念验证)
云计算的情况下,能在瞬间准备好多种模式的环境用于验证,可通过POC来验证运行情况、搭建模式与费用。
在云计算环境下,容量管理与成本管理是一体的。
云计算服务的核心是根据负载使用量收费。由于这种收费模式,原来只有工程师会关注的传送量、I/O数、HTTP请求数等详细的性能指标数据会直接反映在费用上,因此需要经营者掌握这些性能指标及其含义。使用云计算后,容量与成本就联系到一起,因此云计算可能是促使经营者学习容量分析的一个有效手段。
运维:除了应对峰值,在没有业务流量的时间段内动态削减多余的资源,降低成本,也是很有价值的。
扩展阅读:电子书《Linux Perf Master》

扩展阅读
- Linux 性能诊断:负载评估
- Linux 性能诊断:快速检查单
- 操作系统原理 | How Linux Works(一):启动
- 操作系统原理 | How Linux Works(二):空间管理
- 操作系统原理 | How Linux Works(三):内存管理
- 操作系统原理 | How Linux Works(三):网络管理

